![[レポート]AWSにおけるエンドツーエンドのデータ統合とデータエンジニアリング #AWSreInvent](https://devio2024-media.developers.io/image/upload/f_auto,q_auto,w_3840/v1733579236/user-gen-eyecatch/kjz2znrlrsevqakguego.jpg)
[レポート]AWSにおけるエンドツーエンドのデータ統合とデータエンジニアリング #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、AWS re:Invent 2024参加中のデータ事業本部の渡部です。
今回は4日目の【ANT350-R | End-to-end data integration and data engineering on AWS】のWorkshopをレポートします。
なぜ参加したのか
AWSのデータ統合・データエンジニアリングについて改めて触ってみたかったからです。
今回のワークショップの内容はひととおり触った経験がありましたが、今一度実際に触りつつ特徴を掴んで、今後のアーキテクチャの提案活動に活かしたいと思う次第です。
セッション概要
概要
エンドツーエンドというだけあって、非常に多くのデータ系サービスやファイル形式に触れることができました。
ワークショップの具体的内容は、ストリーミングデータとトランザクションデータをデータソースとして、データ品質を保ちつつ、LakeFormationで行レベルアクセス制限を課して、IcebergテーブルをAthena、Redshift Spectrumでクエリするというものでした。
もしもこのワークショップがいつでも触れるのなら、データエンジニアの入門として使用するのがいいと思うほどの満足感がありました。
なお先日発表されたSageMaker Unified Studioについては今回のワークショップ対象外です。
以下、セッション説明です。
This comprehensive workshop equips data engineers, data scientists, data analysts, and data developers with the skills to navigate their entire data journey on AWS. Gain expertise in different data ingestion and integration techniques; explore data lake and data warehouse storage solutions; build data transformations; build, scale, and monitor data pipelines; deploy governance at scale; and dive into different data transformation methods to unlock data’s true potential. Leave this workshop empowered to build data products and manage robust transactional data lakes and data warehouses, transforming raw data into actionable intelligence. You must bring your laptop to participate.
この包括的なワークショップは、データエンジニア、データサイエンティスト、データアナリスト、データ開発者に、AWS上での完全なデータジャーニーを進めるためのスキルを提供します。様々なデータ取り込みと統合技術の専門知識を習得し、データレイクとデータウェアハウスのストレージソリューションを探索し、データ変換を構築し、データパイプラインの構築・スケーリング・モニタリングを行い、大規模なガバナンスを展開し、データの真の可能性を引き出すための様々なデータ変換手法を掘り下げます。このワークショップを通じて、データ製品の構築と堅牢な取引データレイクおよびデータウェアハウスの管理が可能になり、生データを実用的なインテリジェンスに変換する力が身につきます。参加にはラップトップの持参が必要です。
スピーカー
- Asif Abbasi, Principal Solutions Architect, Amazon Web Services
- Stuti Deshpande, Big Data Specialist Solutions Architect, Amazon Web Services
セッション内容
ワークショップに関する事前説明
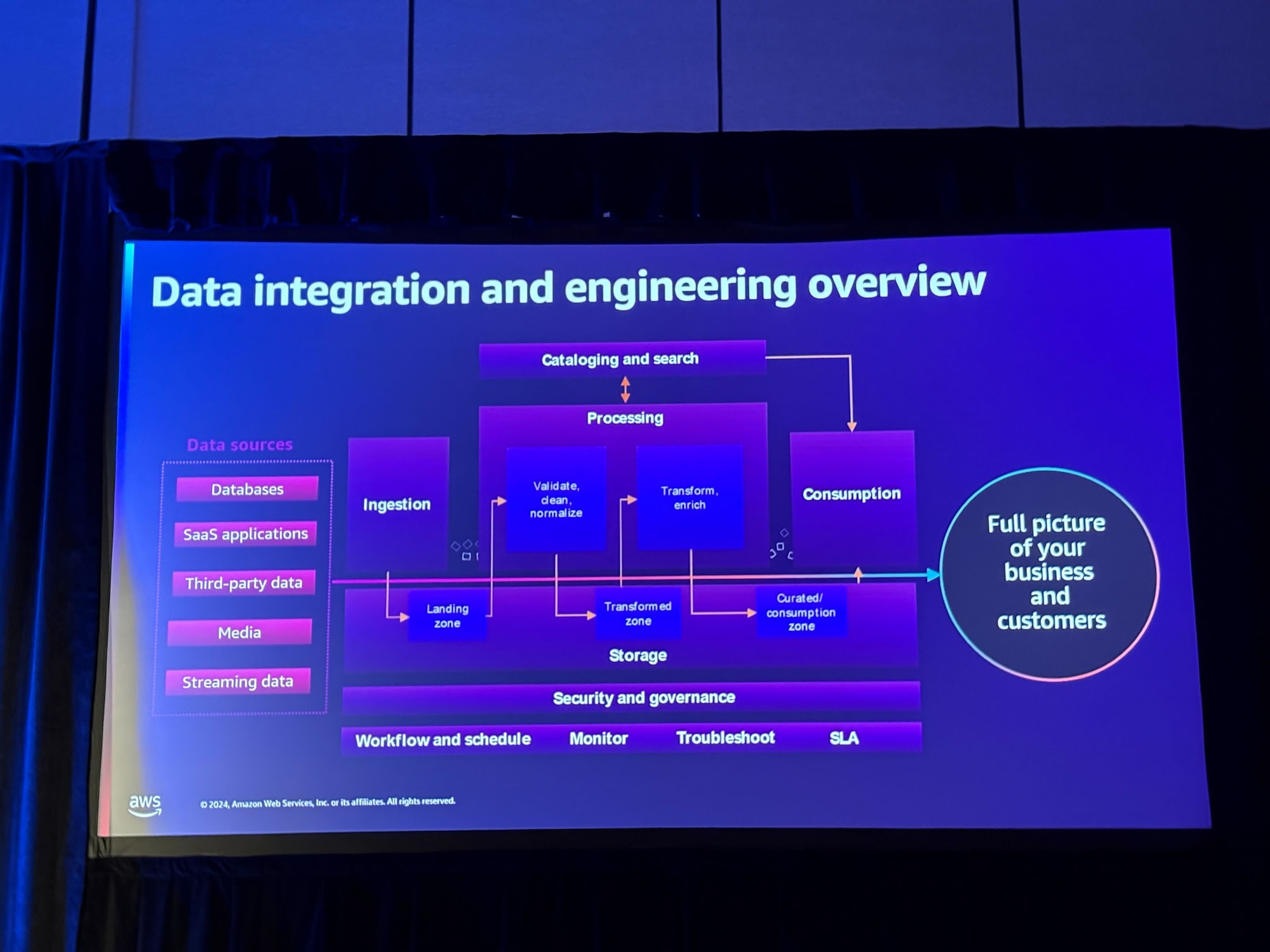
まずワークショップの冒頭でデータソースからデータ利活用に至るまでの概観の説明がありました。
多種多様なデータソースから、それぞれに適した方法でデータ収集・整形をしつつ、データカタログのメタデータ管理、データセキュリティなどを管理していく必要があることが示されました。
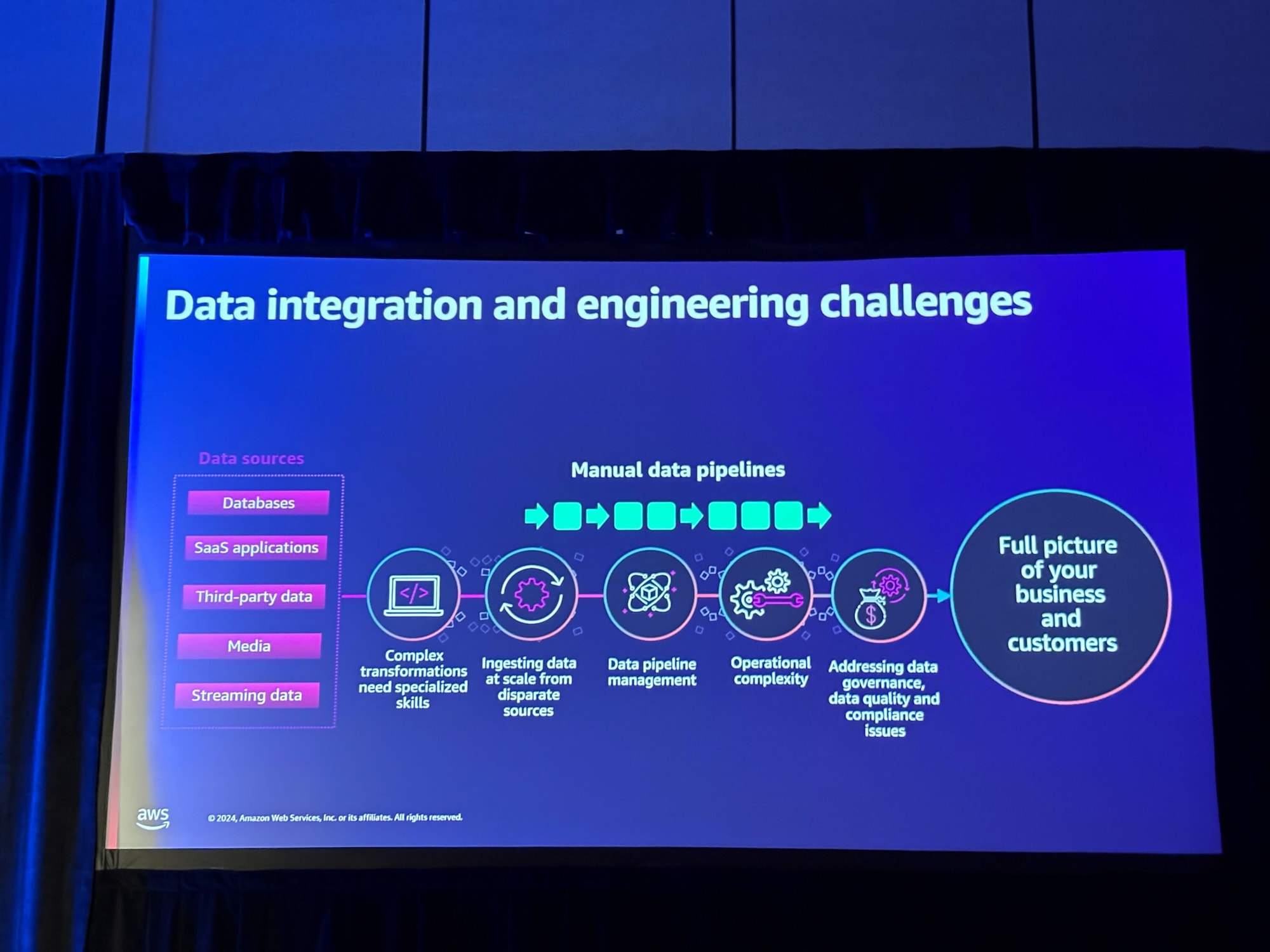
課題として以下が紹介されました。
- 複雑な変換には専門的なスキルが必要
- 様々なソースからの大規模なデータ取り込み
- データパイプラインの管理
- 運用の複雑さへの対応
- データガバナンス、データ品質、コンプライアンスの課題への対処
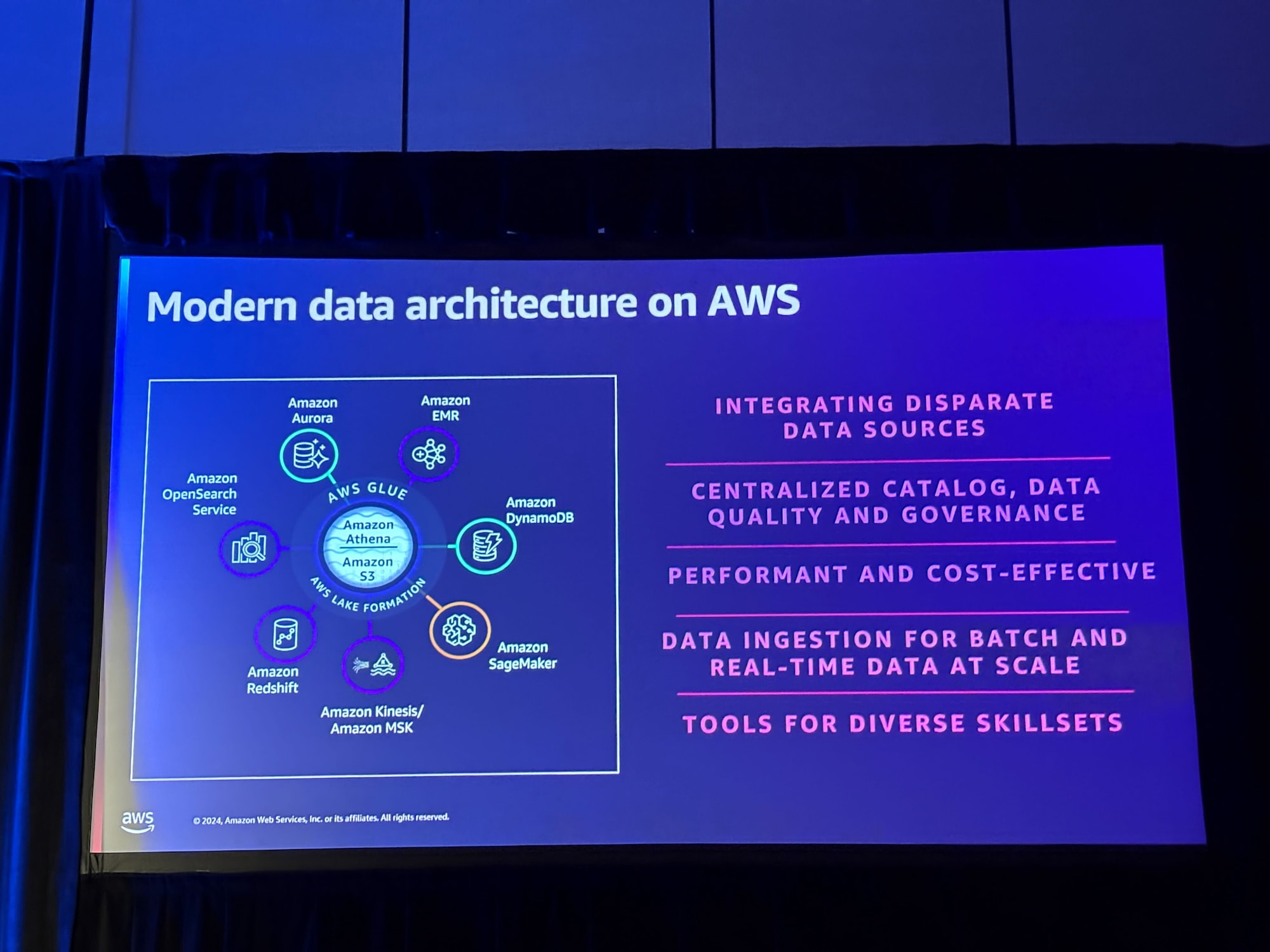
上記であげられた課題に答えるAWSのモダンデータアーキテクチャについての説明がなされました。
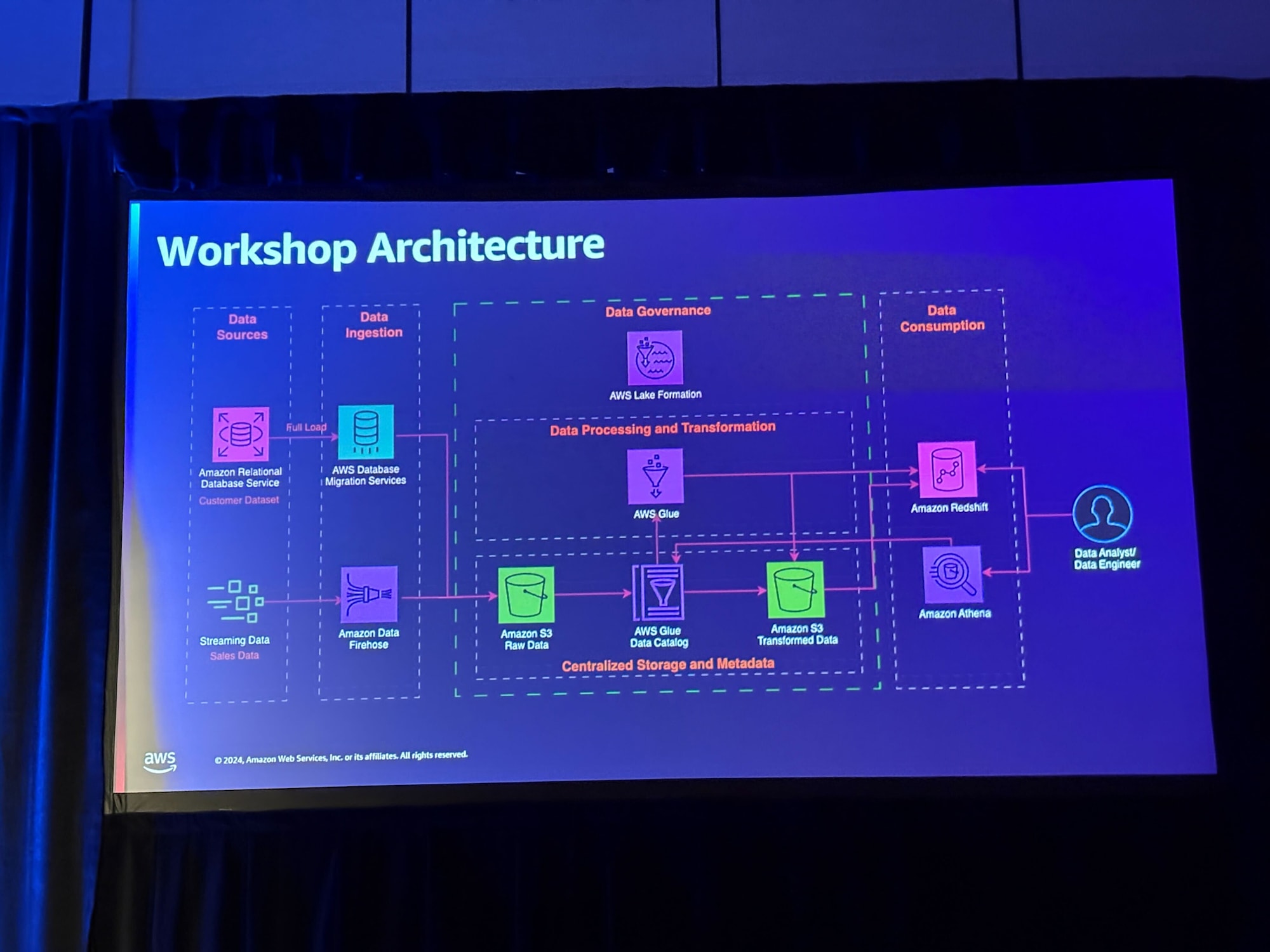
先ほどの概念図を実際の構成図としたものが今回のワークショップで作り上げるアーキテクチャです。
ワークショップのアジェンダは以下の通りです。
- Module 1 - Data Ingestion
- Real time streaming with Amazon Data Firehose
- Batch ingestion with AWS DMS
- Module 2 - Data Processing
- Data Processing & Data Quality with AWS Glue
- Module 3 - Data Governance
- Fine Grained access control with AWS Lake Formation
- Module 4 - Data Analysis
- Data Analysis with Amazon Redshift
- Module 5 - Optional
- Time Travel with Apache Iceberg

ワークショップ内容
ここからはワークショップ用に用意された環境で、Webテキストを見ながら構築していきました。
個人的に面白かった部分のスクリーンショットを添付します。
まずはストリーミングデータを用意するために使用したKinesis Data Generatorです。
今回はすでにData Firehoseとストリーミング先のS3バケットは用意されていたため、Kinesis Data Generatorでデータを用意するところを触りました。
このサービスを実際に触ったことがなかったのですが、テストデータを簡単に作成して再利用もできるということで、非常に便利だなと感じました。
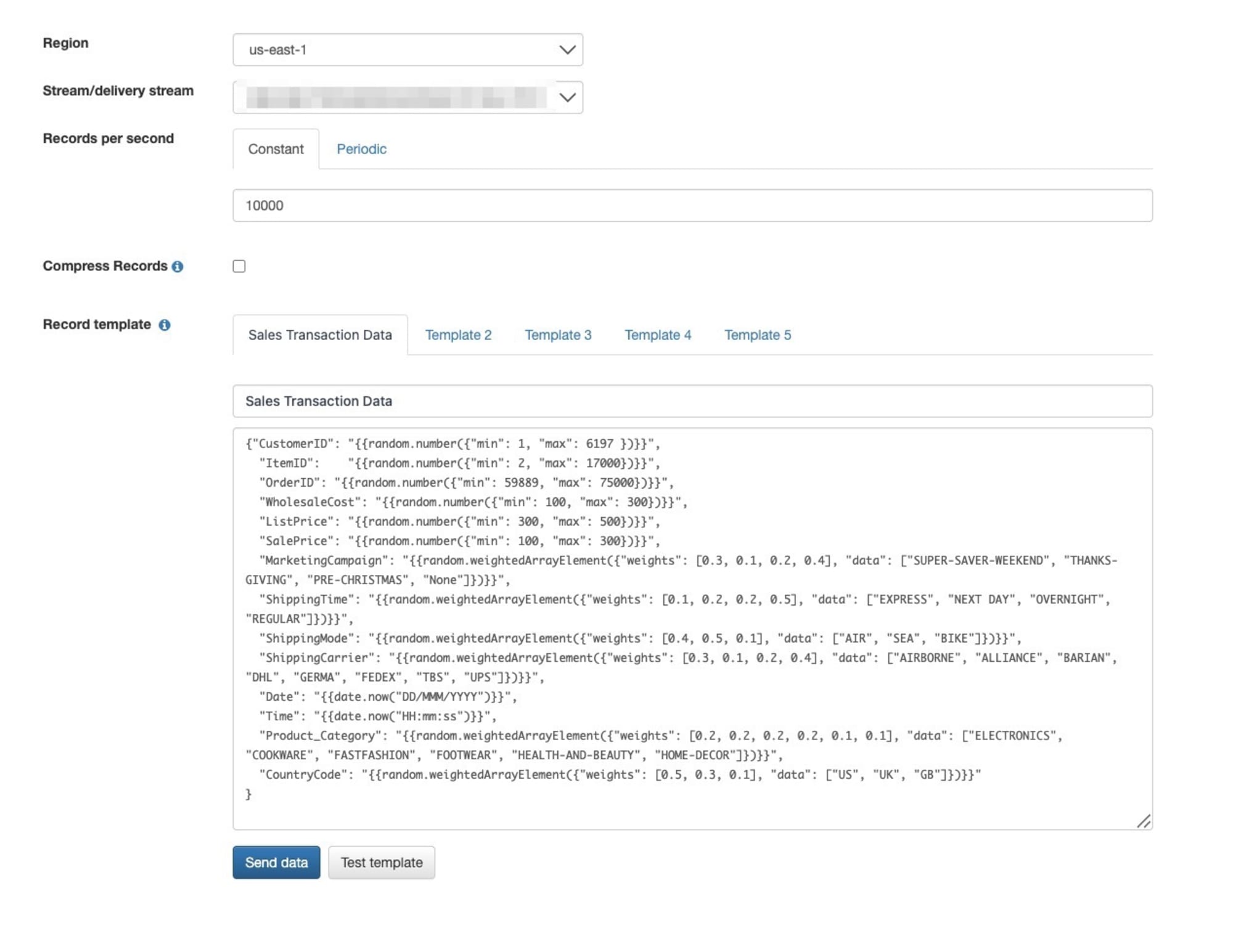
実際にストリームにデータが送られている様子です。
データがS3に配信されているのを確認して、配信はSTOPしました。

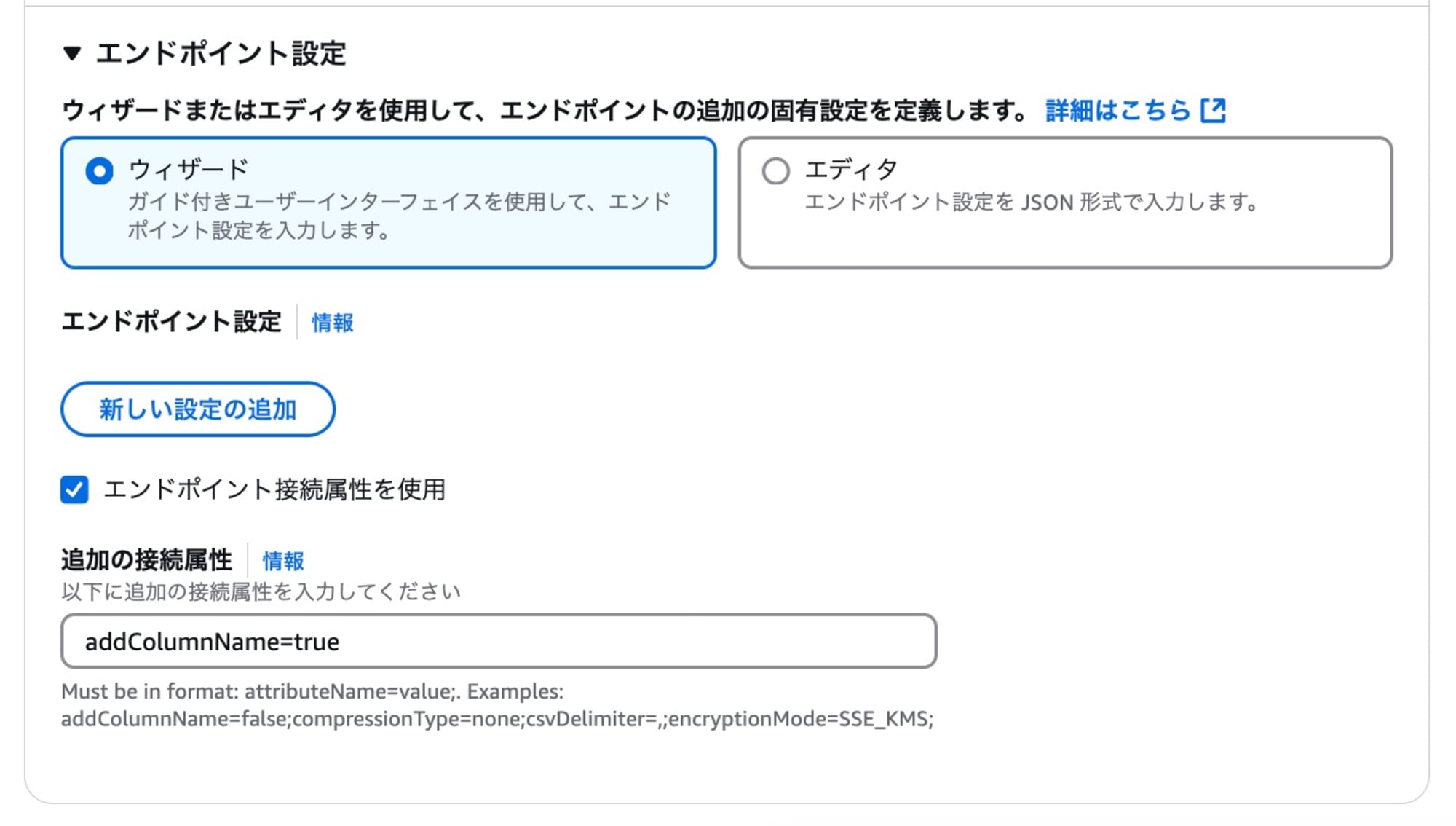
続いてDMSを使用してRDSからS3へデータを一括移行しました。
追加の接続属性addColumnName=TrueでCSVファイルに項目名も合わせて移送しました。
S3をGlueでクロールしました。
データソースから収集したデータが管理されています。

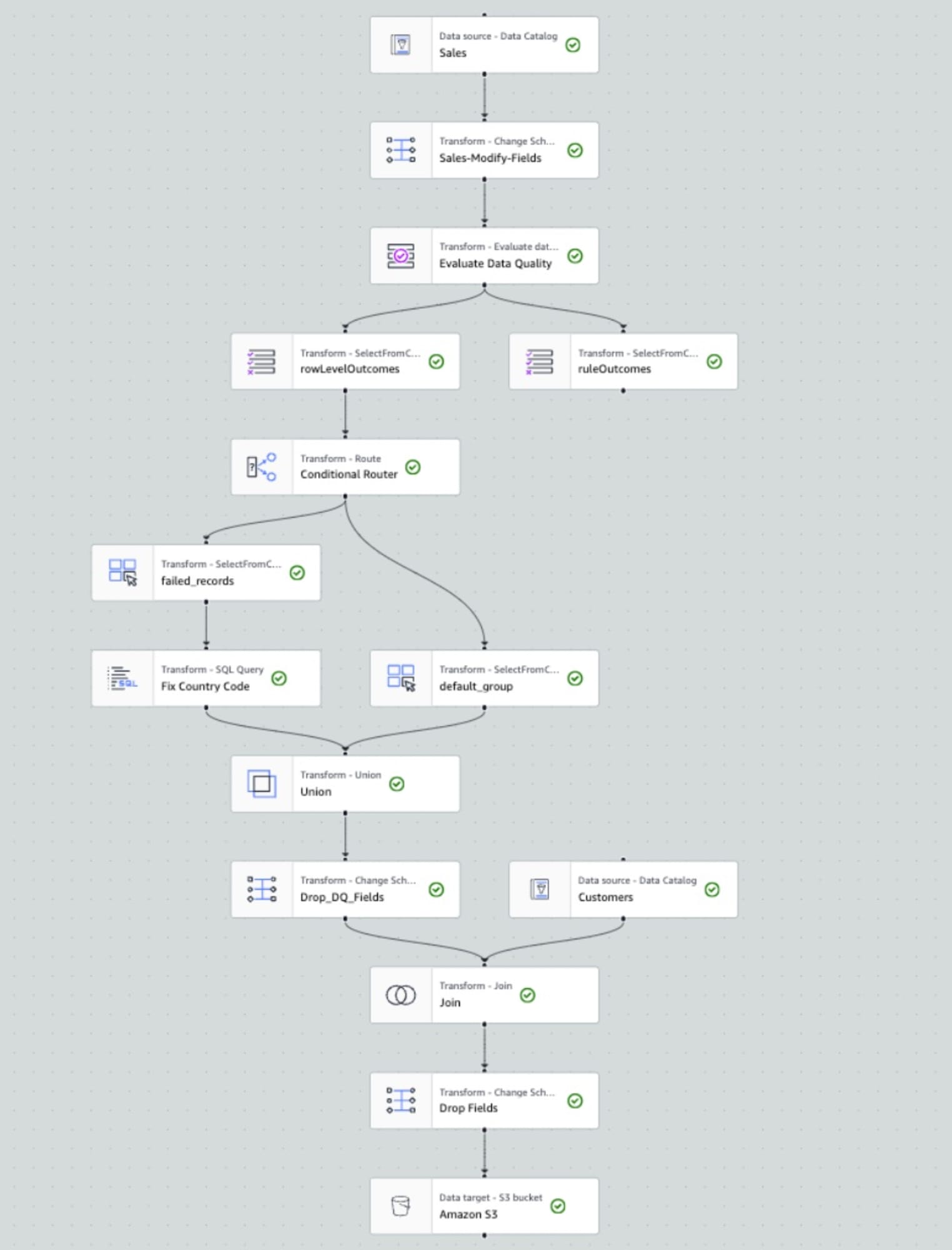
ここからはGlueでVisual ETLを使用して、データ要件に合わないデータがあれば補正をして、分析用のIcebergテーブルを作るパイプラインを作成しました。
少し慣れは必要なのですが、多少複雑なパイプラインでも簡単に視覚的に作成することができます。
実際にAthenaとRedshift Spectrumで作成したS3のIcebergテーブルをクエリしました。
またそのときにAthenaではLakeFormationのData Filterでの行レベル制限、
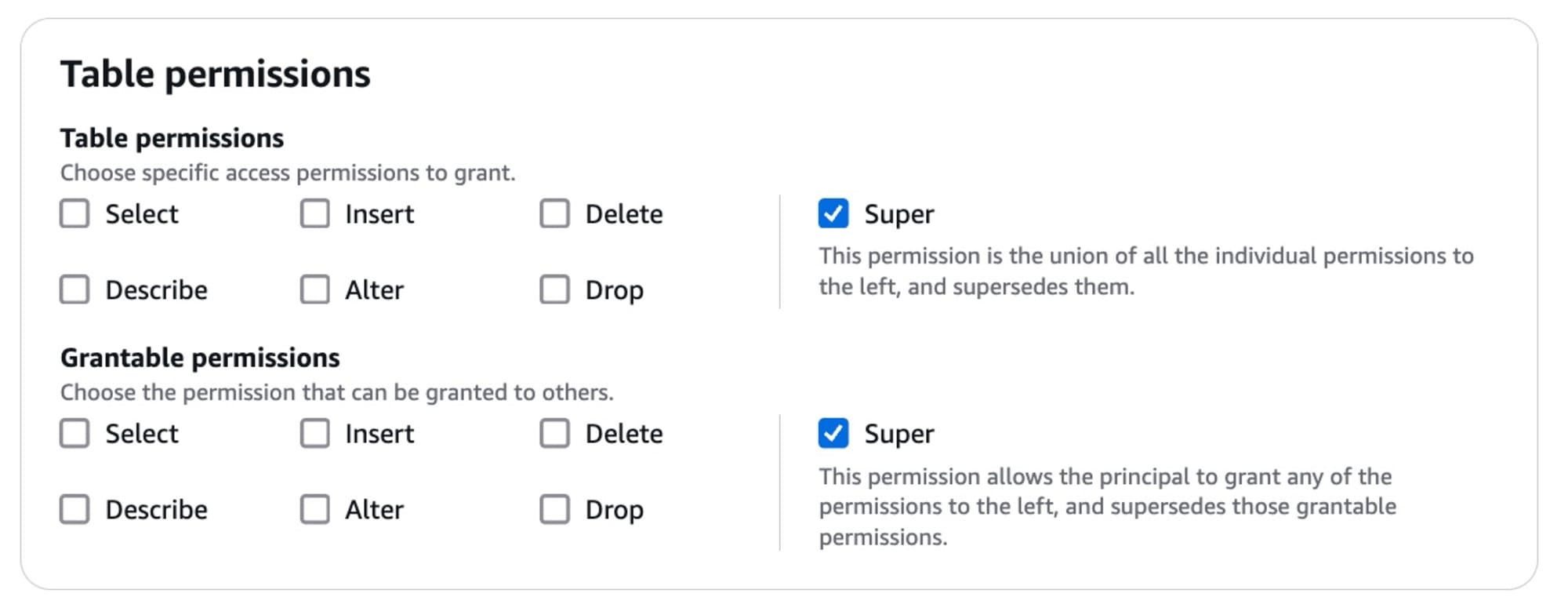
Redshiftについては接続に使用しているIAMがLakeFormationでアクセス許可が設定されていなかったので、実際にテーブルへのアクセスを許可する設定を行いました。
下記はIcebergテーブルへのSUPER権限を特定のIAMロールに許可をしている様子です。
またRedshiftではQを使用した自然言語によるSQLの生成も行いました。
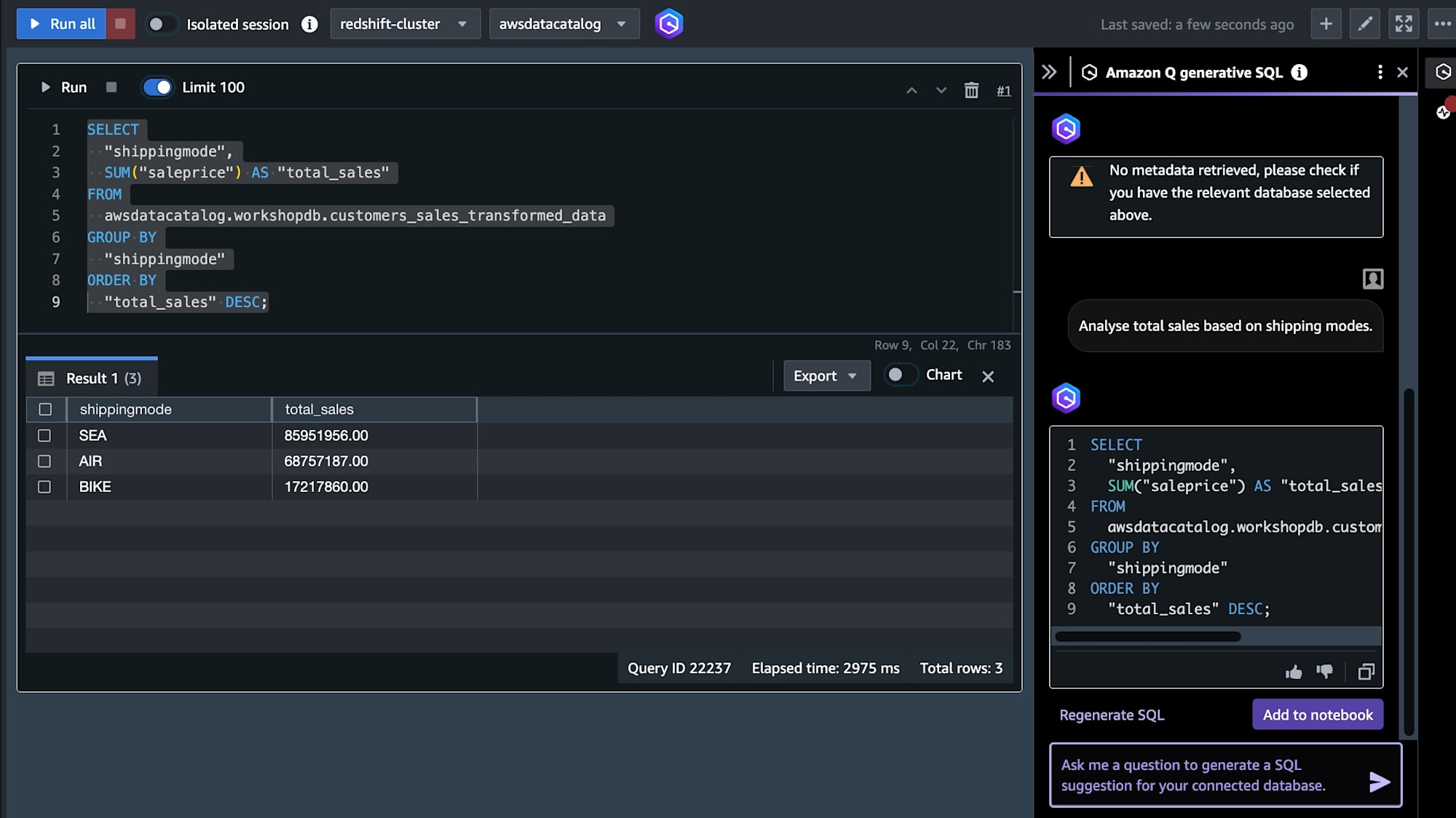
最後におまけとして、ワークショップのあとにIcebergを触ってみました。
まずはIcebergテーブルの1項目を単純に+20するUpdate文を実行します。
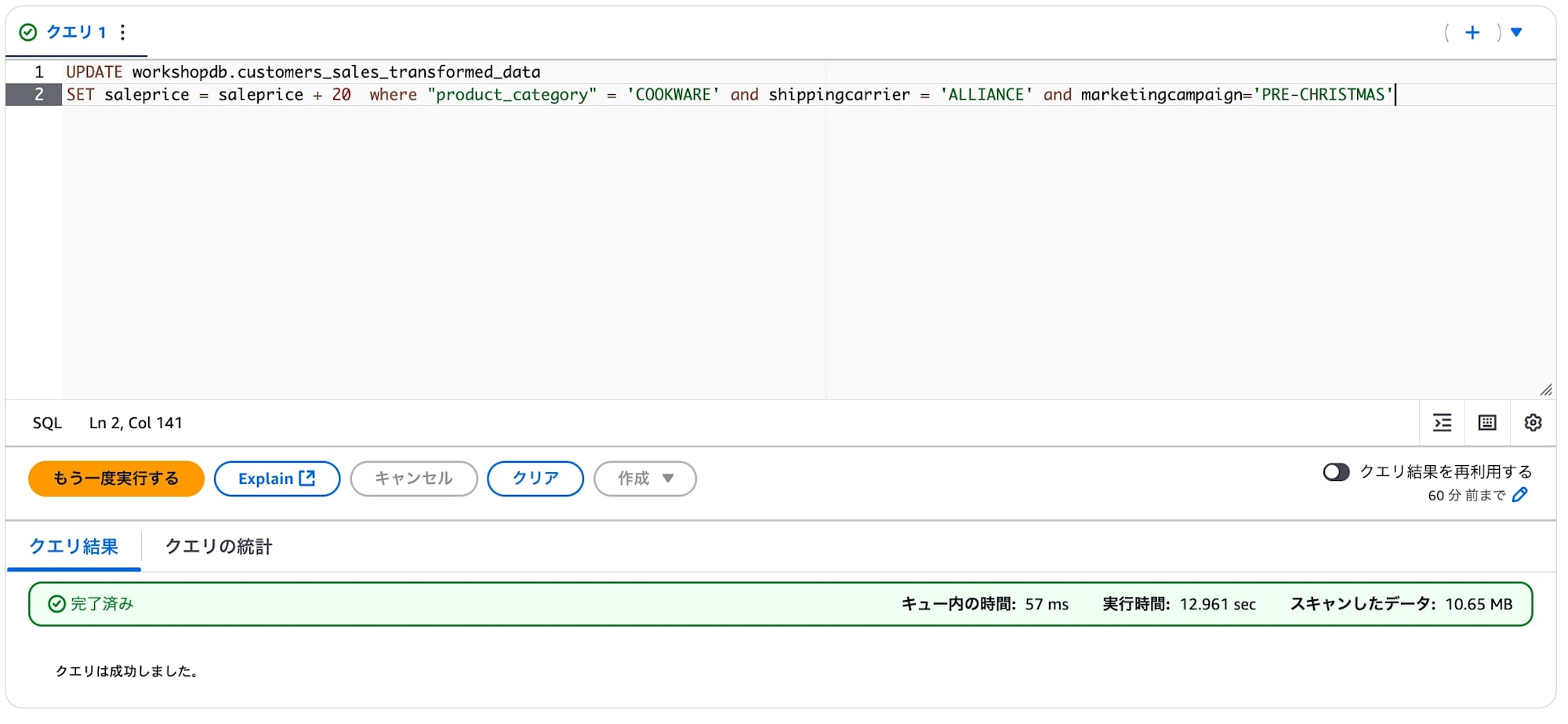
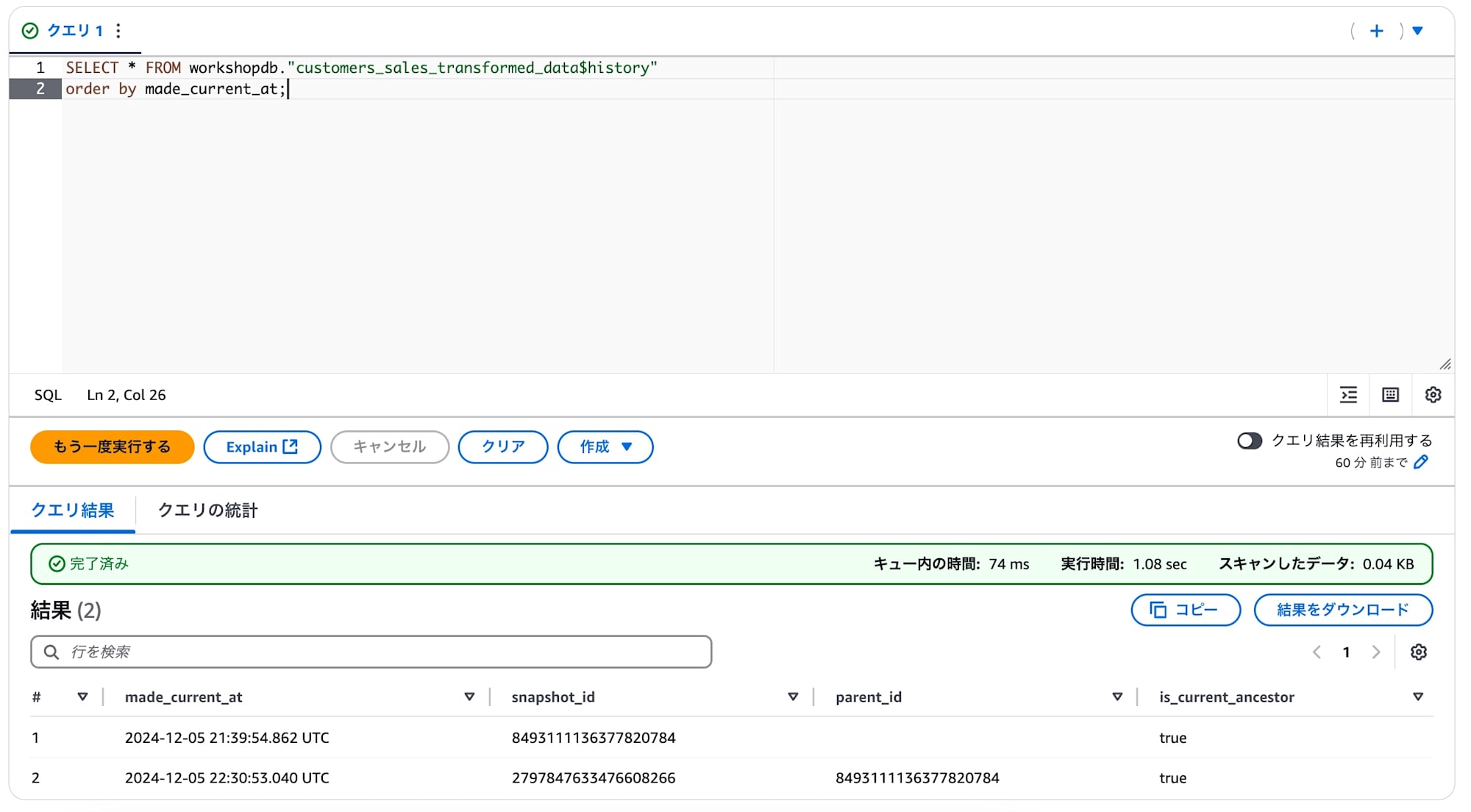
Icebergの過去履歴を持つ様子を確認します。
$historyをテーブル名に付け足してクエリを叩くと、先ほど更新した際のスナップショットidがあることが確認できます。
実際にスナップショットのIDを指定してクエリをすることで結果が違うことが確認できました。
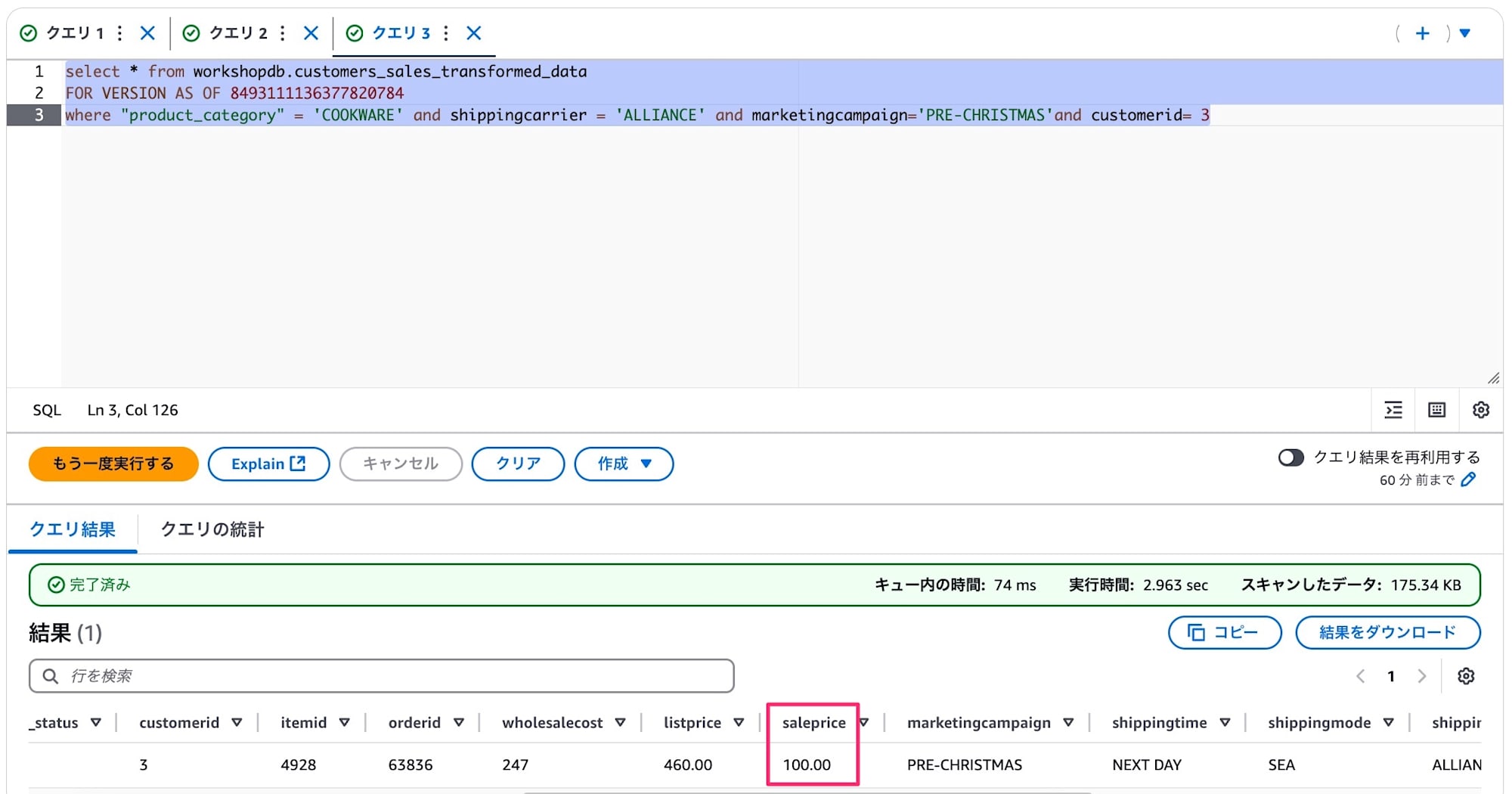
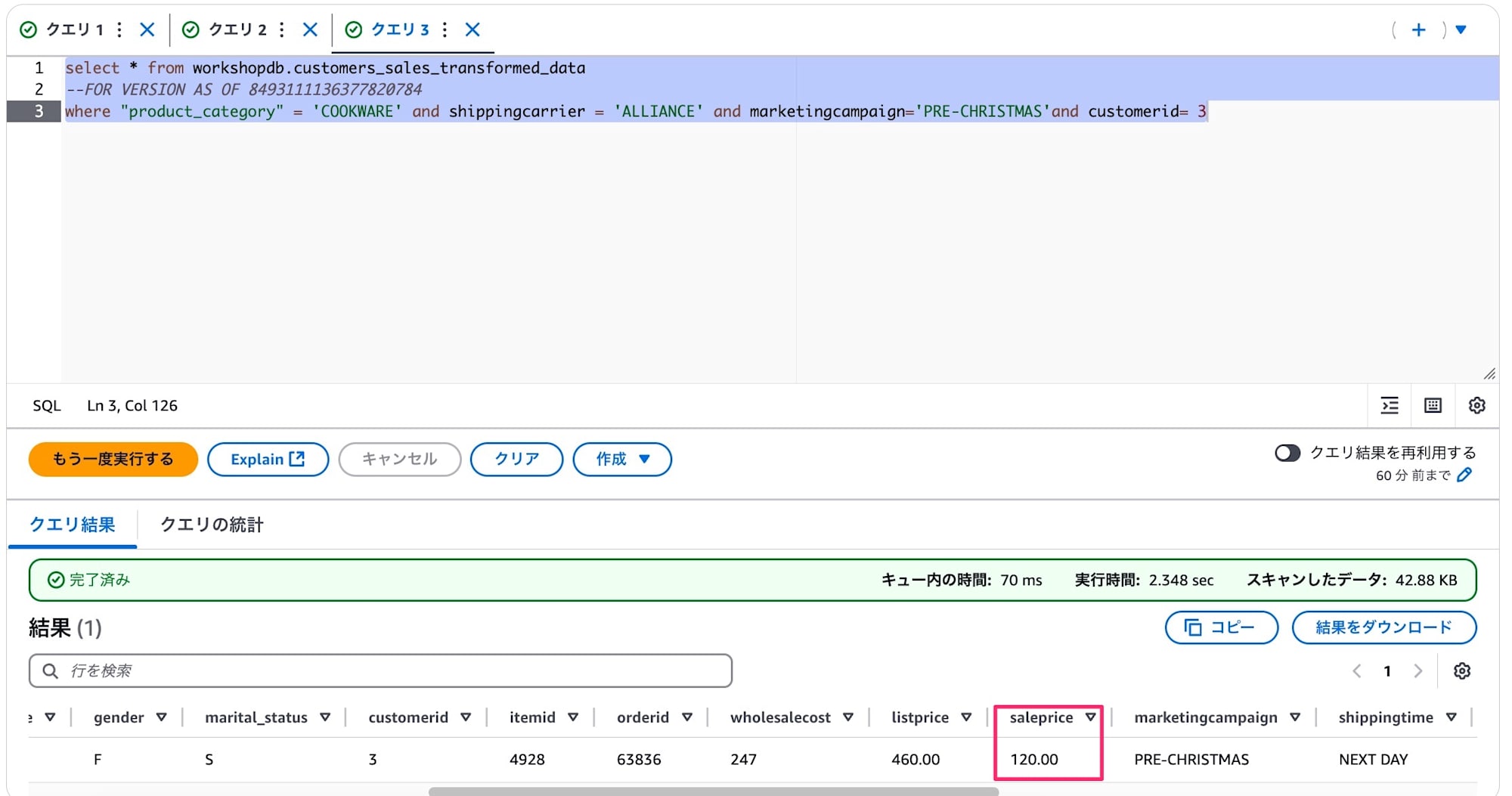
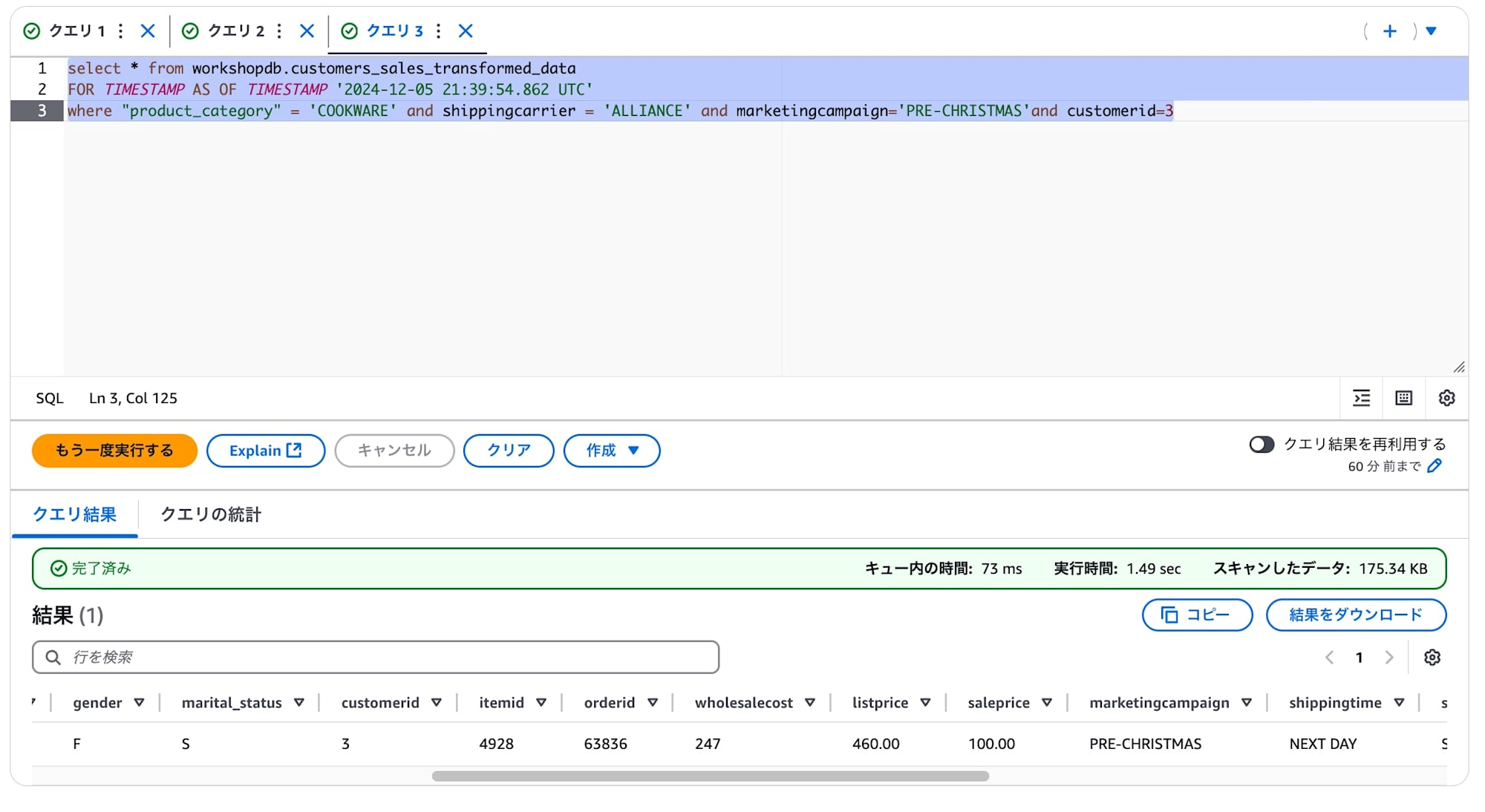
スナップショットIDではなくタイムスタンプの指定でも同じように過去データが参照できました。
以上ワークショップのまとめでした。
やはり改めてサービスを触ってみると、色々な発見がありました。
GlueのVisual ETLが使い方がわかると使いやすそうであること、RedshiftのQによるSQL生成が叩き台としての使用に使えそうであること(Bedrock Knowledge Basesの構造化データ対応も発表されましたね)が、自分の体験をもって知れたのがよかったです。
今回のアーキテクチャを基本にZero-ETLやIceberg用に先日発表されたS3 Tableを使用するというのが、現状のAWSで実現するモダンデータアーキテクチャとなると思うので、ここは今後押さえておきたいところです。










